최근 멀티에이전트 강화학습(MARL) 분야를 공부하면서 COMA 논문을 읽어보았다.
MARL을 이용해보고 싶어 라이브러리와 모델을 검색해봤더니 pyMARL이라는 라이브러리가 나왔다.
MARL 분야에서는 다양한 환경이 있지만 스타크래프트2를 이용해 멀티에이전트를 학습시키기도 한다.
멀티에이전트 분야에서는 코드를 어떻게 구성해 에이전트들을 컨트롤하는지 분석해보고 싶어 알아보았다.
내가 알아본 깃허브는 https://github.com/oxwhirl/pymarl 으로 SC2를 기반으로 다양한 멀티에이전트 모델을 실험해볼 수 있는 환경을 제공해주었다.

PyMARL 구조 분석
그럼 구조가 어떻게 되어있는지 분석해보자
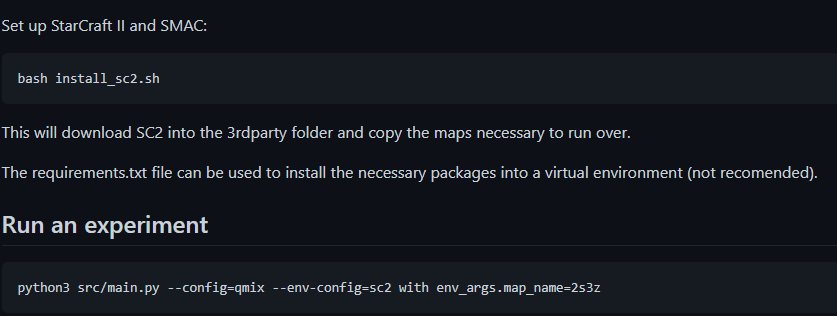
깃허브에서는 src/main.py에 다양한 config를 주어 실험이 가능하도록 만들었으니, main.py 부터 까보았다.

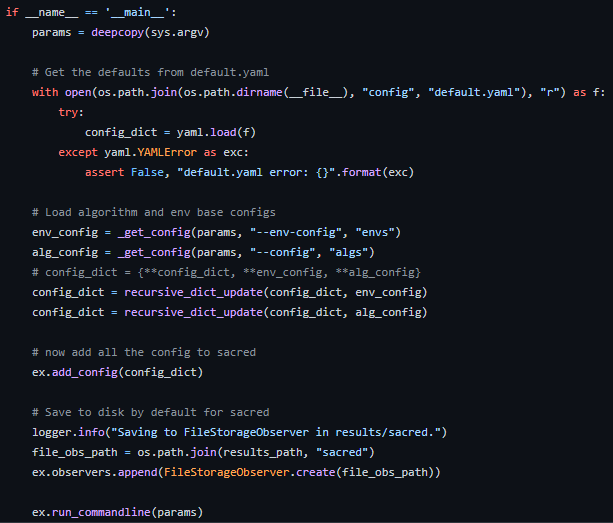
src/main.py 내용 중 일부로 핵심이 되는 my_main함수이다.
자세히 보면 @ex.amin이라는 데코레이터로 감싸져있는데
이는 sacred 라는 딥러닝 기반으로 실험을 로깅할 수 있도록 도와주는 라이브러리다.
요약하면 config로 설정된 환경을 불러오고, 실험을 로깅할 수 있도록 만든 구조라고 보면 된다.
sacred 라이브러리에 관한 자세한 설명은 https://zzsza.github.io/mlops/2019/07/21/python-sacred/ 홈페이지에 있다.
위의 config에 모델명을 설정하고, env-config를 통해 환경을 선택할 수 있고 그 내부 map_name을 통해 상세한 실험목록을 변경할 수 있는 것을 볼 수 있다.
실제로 위의 깃허브는 같은 저자가 만든 https://github.com/oxwhirl/smac 과 연결되어 있으므로 세부적으로 확인해볼 수 있을 것이다.
COMA 코드 분석
해당 깃허브에선 COMA 에 대한 코드도 제공해주기 때문에 어떤 구조로 학습이 이루어지는지 확인해보았다.
참고 : https://github.com/oxwhirl/pymarl/blob/master/src/learners/coma_learner.py
GitHub - oxwhirl/pymarl: Python Multi-Agent Reinforcement Learning framework
Python Multi-Agent Reinforcement Learning framework - GitHub - oxwhirl/pymarl: Python Multi-Agent Reinforcement Learning framework
github.com
논문에서 말하는 COMA 구조는 그림(a)로,
에이전트가 환경 내에서 수행한 결과를 Critic에 보내고, Critic에서 해당 행동의 가치를 평가한다.

COMA(COunterfactual Multi Agents)
이 구조가 코드에는 어떻게 적용되어있는지 확인해보자.
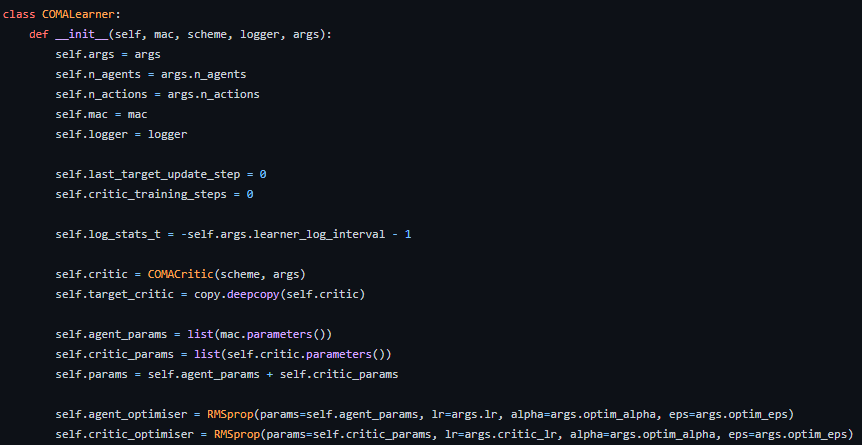
에이전트 개수와 액션 개수를 파라미터로 두게 되어있고,
mac라는 Multi Agent Controller를 둔 것, COMACritic이라 하여 Critic구조도 만들어넣은 걸 볼 수 있다.
MAC(Multi Agents Controller)
MAC에 관한 기본적인 구조는 아래 홈페이지에서 확인할 수 있다.
https://github.com/oxwhirl/pymarl/blob/c971afdceb34635d31b778021b0ef90d7af51e86/src/controllers/basic_controller.py

MAC는 컨트롤러답게 행동을 선택하는 부분이 들어가있다.
에이전트에 대한 모델 부분은 함수 내에 _build_agent 함수가 있는데 이 부분은 미리 설정된 모델로 불러온다.
이후, forward 함수에서 게임으로부터 들어온 입력을 agent_inputs이라는 변수로 변경하여 에이전트에 입력,
에이전트가 결과를 출력하도록 만든다.

결과는 [B, U, -1] 타입으로 Batch 사이즈 별로 에이전트마다 어떻게 행동할 것인지 담은 텐서가 나오게 된다.
다시 coma_learner로 돌아와보자.
coma_leaerner.py 내에는 위의 mac를 받아와 학습시키는 train 함수가 있다.


게임 내에서 batch라는 config 내부에 많은 데이터들이 담겨있는 것으로 보이는데,
하이라이트된 부분을 보면 self.mac.forward 함수를 통해 위의 mac이 진행되어 결과를 mac_out에 담는 것을 볼 수 있다.
코드 내부에는 mask라는 변수가 있는데, 이는 SC2 기준에서 많은 행동들이 가능하기에 유효한 행동을 제외한 나머지들을 없애는 작업을 의미한다.
마지막 mac_out[avail_actions == 0] = 0 을 보면 유효하지 않은 행동은 0으로 만드는 작업을 볼 수 있다.
이후 내용은 actor-critic 모델에서 흔히 쓰이는 구조로 advantage 값을 구해 로스를 취하여 학습을 진행한다.
모델을 다시 확인해보면, env -> actor -> mac 까지의 학습 구조는 확인했지만,
코드 내에서 critic을 학습하는 과정은 아직 나오지 않았다.
coma_learner.py의 train 함수를 잘 보면 _train_critic 함수가 있는데, 여기에서 critic에 대한 학습이 이루어진다.
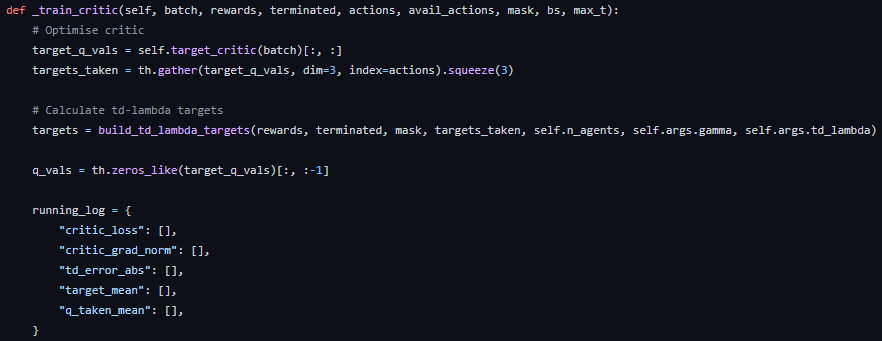
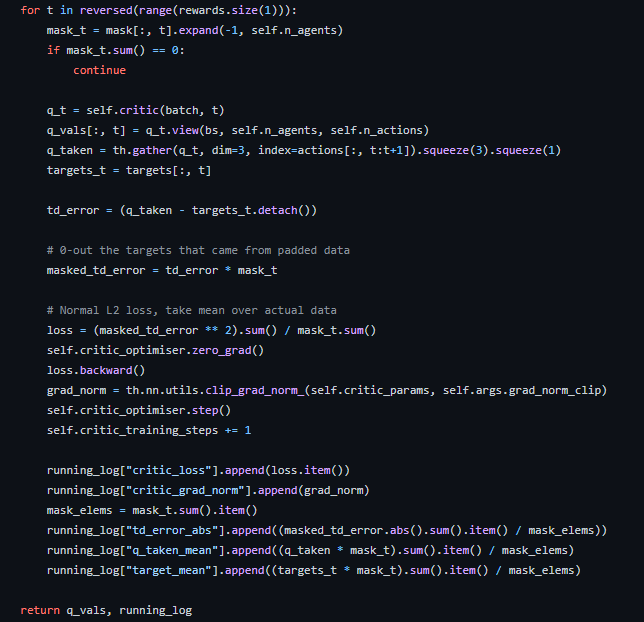
핵심적인 부분을 보면 마지막 reward로부터 처음 reward까지 역순으로
모델이 평가한 q값과 목표 q값의 차이를 계산해 td error를 취하면서 로스가 계산되는 것을 볼 수 있다.
pymarl 환경에서 제공하는 COMA를 뜯어보는데, 에이전트가 관측하는 값은 환경에 따라 바뀌기에
더 확실하게 잡을 순 없지만, agent가 어떤 값을 얻어서 mac에 넘기고,
mac는 agent들로부터 받은 값을 어떻게 취합해 학습을 시키는지,
COMA의 critic 함수는 어떻게 학습이 이루어지는지 알 수 있었다.
'AI | ML > Reinforcement Learning' 카테고리의 다른 글
| [RL] Beginner Guide (3) | 2024.01.16 |
|---|---|
| [ML-Agent] Unity 게임을 gym.Env 환경으로 변경 (0) | 2021.09.03 |
| [Unity] ML-Agents 설치 및 테스트해보기 (2) | 2021.08.13 |
| [RL] Stable-baselines3 모델 커스터마이징 (10) | 2021.08.02 |
| [RL] stable-baselines3 학습 커스터마이징해보기 (0) | 2021.07.30 |