stable-baselines3에서는 PPO, A2C, DDPG 등의 강화학습 모델들이 기본적으로 주어진다.
강화학습모델 안에서 내부 모델을 cnn으로 짤지 MLPpolicy를 쓸지 다양한 선택지가 주어지는데
보통은 mlp를 많이 쓰기도 하지만 cnn으로 진행하는 경우도 있다.
기본 제공 Network
Stable-baselines3에서는 기본적으로 CnnPolicy, MlpPolicy, MultiInputPolicy를 제공하는데
Multi Input은 안써봐서 생략하겠다.
CNN
CNN에서는 convolution 시, kernel_size, stride, padding 등의 파라미터 설정값과
네트워크의 레이어에 따라 추출된 특징이 언제든 변할 수 있다.
아래는 stable-baselines3에서 기본적으로 제공하는 CNN 모델로 첫 레이어부터 kernel_size=8, stride=4 인 걸 보고
내가 생각하는 특징들을 놓칠 수도 있겠단 생각이 들어 수정의 필요성을 느꼈다.
나의 경우는 작은 픽셀을 인식시키는 것을 목표로 하기 때문이기도 하고,
torch.no_grad()로 CNN부분은 학습을 진행하지 않는 걸 보고 뭔가 바꿔보고 싶단 생각이 들었다.

MLP
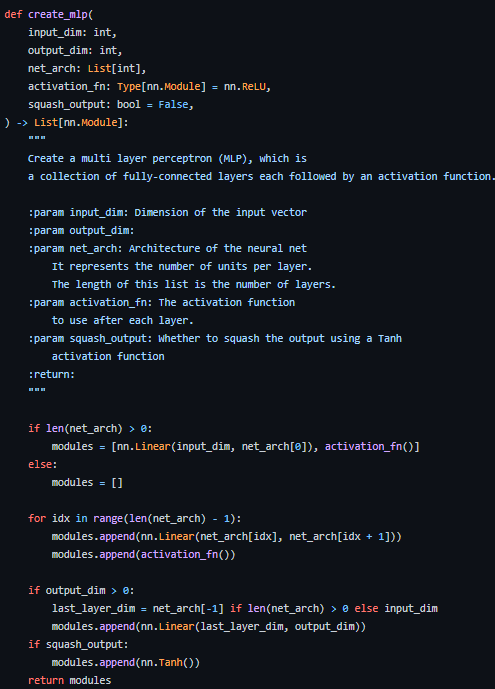
아래는 stable-baselines3에서 제공하는 MlpPolicy 네트워크 생성하는 함수의 내용이다.
mlpPolicy를 이용하는 경우는 아래의 함수를 거쳐서 생성되는데,
mlp같은 경우에는 커스텀하기가 쉽고, 커스텀할 파라미터가 별로 없기 때문에 그냥 진행해도 무방할 것 같다.
변경한 네트워크를 적용해 학습하는 코드는 아래와 같다.
커널 사이즈도 변경해보고, torch.no_grad()를 제거했고, linear 레이어를 추가해봤다.
단점으로는 네트워크가 세세하게 들여다보는 만큼 시간도 늘어나고, 용량도 커졌다는 게 흠이다.
import gym
import torch as th
import torch.nn as nn
from stable_baselines3 import PPO
from stable_baselines3.common.torch_layers import BaseFeaturesExtractor
class CustomCNN(BaseFeaturesExtractor):
"""
:param observation_space: (gym.Space)
:param features_dim: (int) Number of features extracted.
This corresponds to the number of unit for the last layer.
"""
def __init__(self, observation_space: gym.spaces.Box, features_dim: int = 256):
super(CustomCNN, self).__init__(observation_space, features_dim)
# We assume CxHxW images (channels first)
# Re-ordering will be done by pre-preprocessing or wrapper
n_input_channels = observation_space.shape[0]
self.cnn = nn.Sequential(
nn.Conv2d(n_input_channels, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=0),
nn.ReLU(),
nn.Flatten(),
)
n_flatten = self.cnn(
th.as_tensor(observation_space.sample()[None]).float()).shape[1]
self.linear = nn.Sequential(nn.Linear(n_flatten, 64), nn.ReLU())
self.linear2 = nn.Sequential(nn.Linear(64, features_dim))
def forward(self, observations: th.Tensor) -> th.Tensor:
return self.linear2(self.linear(self.cnn(observations)))
policy_kwargs = dict(
features_extractor_class=CustomCNN,
features_extractor_kwargs=dict(features_dim=128),
)
model = PPO("CnnPolicy", env="myGame", policy_kwargs=policy_kwargs, verbose=1)
model.learn(10000)참고 :
https://stable-baselines3.readthedocs.io/en/master/guide/custom_policy.html
'AI | ML > Reinforcement Learning' 카테고리의 다른 글
| pyMARL 구조 분석 + COMA 코드 분석 (0) | 2021.08.23 |
|---|---|
| [Unity] ML-Agents 설치 및 테스트해보기 (2) | 2021.08.13 |
| [RL] stable-baselines3 학습 커스터마이징해보기 (0) | 2021.07.30 |
| [RL] Windows 환경에서 Ray 설치 및 실행하기 (0) | 2021.07.29 |
| [RL] stable-baselines3 모델 학습, 불러오기 (0) | 2021.07.13 |