stable-baselines3 라이브러리를 이용해 학습해보다가
학습 시간을 크게 설정했을 때 저장 주기를 내맘대로 설정하지 못해서 알아보다가 글을 쓴다.
stable-baselines3에서는 학습 중 확인이나, 커스텀을 진행할 때 Callback 메소드를 가져오면 중간과정을 확인할 수 있다.
학습 중 테스트 진행
학습 중에 테스트를 진행하려면 EvalCallback 메소드를 사용하면 되는데,
함수의 전반적인 설명은 이미지를 참고하면 된다.

이 중에 내가 주로 썼던 것은 아래와 같다.
- n_eval_episode : 테스트를 진행할 episode 개수
- eval_freq : 테스트를 진행하는 간격
- log_path : 테스트 결과를 저장할 경로
- render : 가시화할지 여부
- verbose : 0이면 프린트 생략, 1이면 프린트, 2는 디버깅용이다
주의사항
openAI에서 제공하는 강화학습 환경 라이브러리인 gym을 이용해서 만드는 경우에는 DummyVecEnv 코드를 넣어줘야 하는 경우가 있다.
게다가 만약 내가 이용하는 state가 이미지라면 VecTransposeImage를 이용해야 한다.
그렇지 않으면, callback 호출 시 evalCallback에서는 유효하지 않은 env로 인식되어 확인이 어렵다.
나의 경우에는 이런 식으로 진행했을 때, 문제가 없었다.
from stable_baselines3.common.vec_env import VecTransposeImage
from stable_baselines3.common.cmd_util import DummyVecEnv
from stable_baselines3.ppo import PPO
import gym
env = gym.make('Qbert-v0')
env = DummyVecEnv([lambda: env])
env = VecTransposeImage(env)
eval_callback = EvalCallback(env, # best_model_save_path=log_dir,
# callback_on_new_best=callback_on_best,
# log_path=log_dir,
eval_freq=1000,
deterministic=False, render=True)
ppo = PPO('CnnPolicy', env=env, verbose=0)
ppo.learn(time_step, callback=eval_callback)
학습 중 멈추기 (Early-Stopping)
학습 중에 일찍 멈추는 상황이 필요할 땐 StopTrainingOnRewardThreshold 메소드를 가져와 사용한다.
사용법은위의 EvalCallback 메소드를 불러올 때, 넣으면 된다.
import gym
from stable_baselines3 import SAC
from stable_baselines3.common.callbacks import EvalCallback, StopTrainingOnRewardThreshold
# Separate evaluation env
eval_env = gym.make('Pendulum-v0')
# Stop training when the model reaches the reward threshold
callback_on_best = StopTrainingOnRewardThreshold(reward_threshold=-200, verbose=1)
eval_callback = EvalCallback(eval_env, callback_on_new_best=callback_on_best, verbose=1)
model = SAC('MlpPolicy', 'Pendulum-v0', verbose=1)
# Almost infinite number of timesteps, but the training will stop
# early as soon as the reward threshold is reached
model.learn(int(1e10), callback=eval_callback)
레이어 튜닝, 커스터마이징
학습 중에는 내가 입력하는 특징에 따라 네트워크를 깊게 하거나, 파라미터 수를 변경해야 되는 경우가 생길 수 있다.
내가 쓰는 네트워크에 따라 파라미터 설정이 바뀔 수 있는데,
on-policy 모델인지 off-policy 모델이냐에 따라 그 부분은 직접 확인해야 한다.
기본적으로 파라미터 수정은 강화학습 모델을 설정할 때 policy_kwargs라는 옵션으로 수정할 수 있고,
이외에도 활성화함수도 변경이 가능하다.

나는 A2C 모델을 사용해서 기본적으로 net_arch와 부수적으로 vf, pi를 이렇게 바꿔봤다.
policy_kwargs = dict(activation_fn=torch.nn.Sigmoid,
net_arch=[256, 256, dict(pi=[64], vf=[64])])
마지막으로, 요즘 닷지 게임을 만들어서 강화학습으로 피할 수 있는지 테스트해보고 있는데,
내가 학습에 이용한 코드는 아래와 같다.
from stable_baselines3.a2c import A2C
from stable_baselines3.common.monitor import Monitor
from stable_baselines3.common.callbacks import BaseCallback, EvalCallback, StopTrainingOnRewardThreshold
from dodge_env import DodgeEnv
import torch
time_step = 1e+7
policy_kwargs = dict(activation_fn=torch.nn.Sigmoid,
net_arch=[256, 256, dict(pi=[64], vf=[64])])
env = DodgeEnv()
test_env = DodgeEnv(render=True)
log_dir = 'a2c/'
dodge_env = Monitor(env, log_dir)
callback_on_best = StopTrainingOnRewardThreshold(reward_threshold=-100, verbose=1)
eval_callback = EvalCallback(test_env, best_model_save_path=log_dir,
callback_on_new_best=callback_on_best,
log_path=log_dir, eval_freq=5000,
deterministic=False, render=True)
a2c = A2C('MlpPolicy', env=dodge_env, verbose=0, policy_kwargs=policy_kwargs)
a2c.learn(time_step, callback=eval_callback)
a2c.save('dodge_a2c')
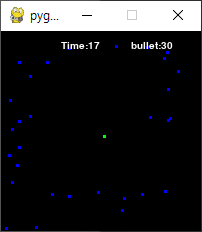
참고
https://stable-baselines3.readthedocs.io/en/master/guide/callbacks.html
https://stable-baselines3.readthedocs.io/en/master/guide/custom_policy.html
'AI | ML > Reinforcement Learning' 카테고리의 다른 글
| [Unity] ML-Agents 설치 및 테스트해보기 (2) | 2021.08.13 |
|---|---|
| [RL] Stable-baselines3 모델 커스터마이징 (10) | 2021.08.02 |
| [RL] Windows 환경에서 Ray 설치 및 실행하기 (0) | 2021.07.29 |
| [RL] stable-baselines3 모델 학습, 불러오기 (0) | 2021.07.13 |
| [RL] 강화학습 모델 라이브러리 stable-baselines3 사용해보기 (0) | 2021.07.13 |