예전에 다양한 시도를 해보면서 겪었던 걸 적었던 글이였는데 오랜만에 발견해서 적어본다.
강화학습을 공부하면서 어디에 적용하면 재밌을까 생각해보다가 테트리스에 적용해보기로 했다.
처음에는 아는 게 DQN밖에 없어서 DQN으로 시도해봤는데, 학습이 전혀 되지 않았다.
나중에 검색해보니, 테트리스가 의외로 search space가 큰 환경이라 단순화해서 접근해보는 것부터 시도해보자고 생각해,블록을 네모로만 한정시켜 보상을 쉽게 줄 수 있도록 적용해봤는데 결과가 아래 그림처럼 좋지 않았다.
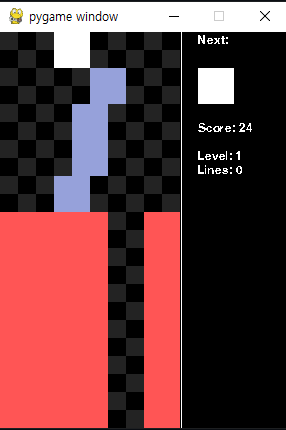
왜 그런지 생각해보다가 보상이 제대로 되지 못했거나, 모델이 맵을 읽지 못한다는 생각이 들어 각각 시도해 보았다.
아래와 같이 보상 체계를 한번 변경해봤다.
- 라인을 지우는 경우 보상 2배로 강화
- 보상 체계 변경 score → removed line
- 구멍 개수만큼 penalty 강화
학습 결과, 여전히 라인을 지우려고 하지 않고, 우연히 지울 뿐이였다.
다시 다른 코드들을 참조하여 보았을 때, 보상보단 인풋을 제대로 주지 못한 것 같아 인풋 구조를 변경해서 학습 시도해봤다.
- 8채널 → 1채널
- input normalize (0~1)
결과는 블럭을 다양한 위치로 쌓으면서 게임이 안 끝나는 데에 집중할 뿐, 스스로 블럭을 지우지는 않았다.
알지 모르겠지만, 옛날 뿌요뿌요의 개구리 패턴처럼 구석으로 쌓기만 했다. (이거 알면 최소 30대)
더 검색해보니 다양한 사례들이 있었고, state에 현재 블록이 무엇인지 넣는 구조인 줄 알았는데, 아닌 것 같았다.
검색해보니 이런 다양한 사례들이 있었다.
state를 바꿔서 시도해본 사례
https://github.com/michiel-cox/Tetris-DQN/tree/66ee640aaa2068f3db4798ddf51f1518c3779cc6
GitHub - michiel-cox/Tetris-DQN: Tetris with a Deep Q Network.
Tetris with a Deep Q Network. Contribute to michiel-cox/Tetris-DQN development by creating an account on GitHub.
github.com
DQN + MCTS 방법으로 해결한 케이스
https://blog.naver.com/devace/221246584746
Q-Learning + MCTS Tetris 강화학습
이종성 devace@naver.com 요약 테트리스(tetris)는 블록(block)이 랜덤(random)하게 나타나는 스토케스틱 ...
blog.naver.com
강화학습은 아니지만, GA 알고리즘으로 시도한 사례
https://blog.naver.com/jh95kr2004/220721085651
[Genetic Algorithm] 유전적 알고리즘 / 테트리스 인공지능
테트리스 (러시아어: Те́трис, 영어: Tetris) 1984년에 러시아(소련)의 프로그래머 알렉세...
blog.naver.com
테트리스 관련 논문 : 테트리스에서 뽑을 수 있는 특징
https://hal.inria.fr/inria-00418954/file/article.pdf
무튼 이런 사례들을 검색해보면서, state를 바꿔보거나 모델을 바꿔봐야겠다고 생각해 state를 바꿔봤다.
테트리스 논문과 위에서 state를 바꿔본 사례를 근거로 이렇게 해보았다.
- 1번째 시도 : State 변경
state를 (20,10) 행렬에서 [hole in rows] + [hole in col] + [max_height - min_heght] 의 33개 state로 바꿔서 해봤는데, 학습이 잘 되지 않아 실패했다.
- 2번째 시도 : State 변경 2
위의 특징들에서 [hole in rows]를 제외한 끼인 정도로 변경해봤고, 벽에 인접한 블록 수를 추가했다. 결과는 잘 끝나는 데 집중할 뿐, 블럭을 지우려 하지 않는 현상이 그대로 발견됐다.
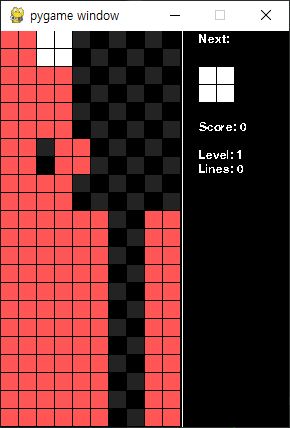
- 3번째 시도 : 논문에서 많이 쓰이는 특징대로 변경 시도 -> 실패
(max_height, rows_with_holes, max_well_depth, landing_height, adjacent_wall_count, sum_horizontal_hole, sum_culmative_wells, block_type, rotate_state)
- 4번째 시도 : 3번째에서 특징 대비 블록이 다양한건가 싶어 블록도 다양하게 해봤는데 여전히 잘 안 됐다.
- 5번째 시도 : 이미테이션 러닝으로 10 에피소드 정도 학습시켜 문제를 알려주는 방식도 시도해봤지만, 큰 진전이 없었다.
- 6번째 시도 : 모델이 state를 해석하지 못하는 건가 싶어, width를 키워봤지만 실패
- 중간 변화
학습속도가 느린 것 같아, multi-processing으로 변경했다.
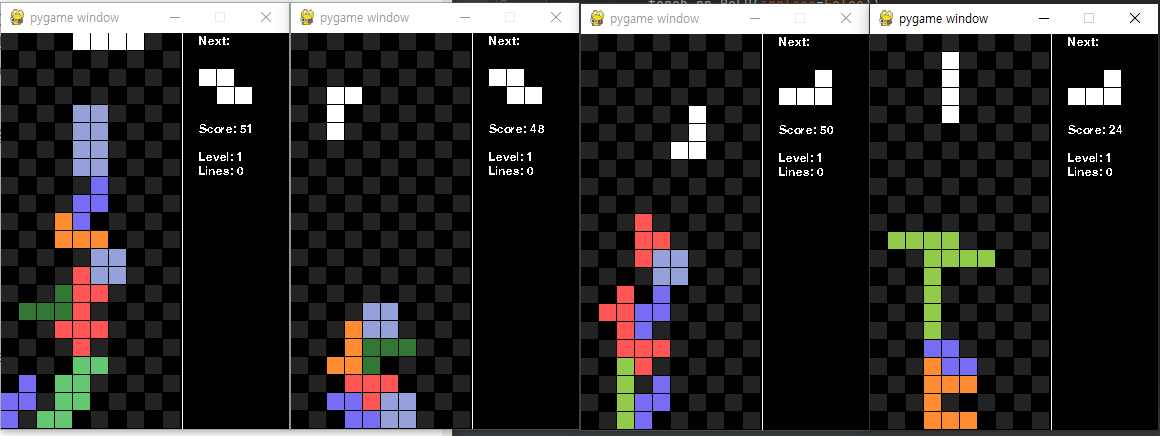
그러다가, 아 이놈의 실수...
model 부분에서 softmax로 인해 보상이 감소되는 현상을 발견해서 softmax 함수를 수정했다.
이후 다시 원래대로 돌려 진행마다 +1로 변경하고, 게임오버 패널티를 1라인으로 설정했다.


이러고 나니, 원래의 문제상황들은 잘 해결했는데, 편법으로만 가길래 맵에 랜덤으로 구멍을 뚫게 바꿨다.

이러던 중에 재밌는 걸 발견한 게, 일반적인 게임방식대로 내려갈 때마다 점수를 줬더니 빨리 내려가려고만 하는 현상을 발견해서, 한 틱당 점수를 +1로 한번 바꿔봤다.
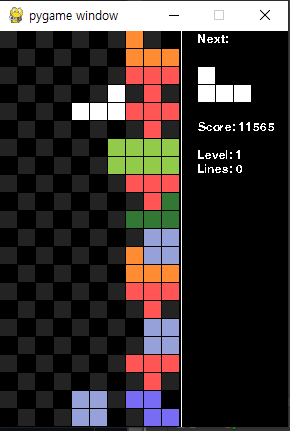
그랬더니, 더 웃긴 게 어디서 버그를 찾아가지곤 구석에서 rotate가 안되는 에러를 이용해서 점수만 얻는 현상이 있어서 다시 내려갈 때마다 점수를 얻도록 원복시켰다. 어이없었다... 이래서 개발자들이 버그 유저를 싫어하나보다.
이렇게 계속 실패만 하다간 해결해보고 싶은 마음이 풀리지 않을 것 같아 다른 사람의 코드를 한번 적용해보고, 원인을 분석해보기로 했다.
https://awesomeopensource.com/project/nuno-faria/tetris-ai
내가 생각하는 기준으로는 블록이 주어졌을 때 현재 포지션에 대한 특징을 주고 판단하면서 찾아가는 알고리즘일 거라 생각해왔었다. 검색해본 결과 움직이면서 최적의 action을 찾는 것도 맞지만, 현재 블록이 주어졌을 때 블록이 들어갈 수 있는 모든 공간을 탐색해보고 그 중에 최고의 선택이 어느 곳인지를 알려주고 찾는 방식으로 진행하고 있는 것 같았다.
아래는 다른 사람이 같은 DQN을 이용해 테트리스를 이용한 깃허브다.
- https://github.com/nlinker/tetris-ai-python
- https://github.com/nuno-faria/tetris-ai
- https://github.com/michiel-cox/Tetris-DQN
그리고 이 내용을 이해해보고 직접 학습해본 결과는 이렇다.

후기 및 정리
테트리스가 2차원 행렬이여서 CNN을 기반으로 하면 될 줄 알았는데, 알고 보니 MLP 로 접근했다.
모델을 짤 때 action을 softmax로 진행했었는데, argmax로 진행해야 된다는 걸 알았다.
그렇지 않으면 보상이 0~1로 현재 score보다 작아서 Q-learning이 되지 않는다는 걸 배웠다.
Q-learning 기준으로 테트리스에서는 현재 블록을 기준으로 특징 추출하면서 최적의 목표를 찾는 게 못해서 그런건지 안 되는 것 같다. 그래서 각각의 행,열 별로 Q-Table을 직접 사람이 작성해줘야 하는 것으로 보인다.
아래는 예시 코드다.
for col in range(possible_cols):
for r_index in block.rotations:
states[(col, r_index)] = get_state_properties(board)
# get_state_properties를 통해, col, rotate상황일 때의 특징을 추출해 가져옴현재 아는 모델이 많지 않아 DQN을 위주로만 적용하였는데 나중에는 다른 강화학습 알고리즘으로 가능한지 공부해보고 시도해봐야겠다.
추가 후기
다른 계열의 논문이나 자료들을 읽어보게 되면서 테트리스에 적용할 수 있을까 생각해봤다.
TRPO, PPO 와 같은 Policy Gradient 계열의 논문을 읽어보게 됐는데 어떻게 구현할까 조금 막막하던 와중에, 마침 다양한 강화학습 모델을 사용할 수 있는 stable-baseline3 을 알게 되었고, 테트리스에 적용시켜서 학습시켜봤다
원래 있던 DQN부터 PPO에도 적용시켜 봤는데 계속 개구리 패턴만 됐다.
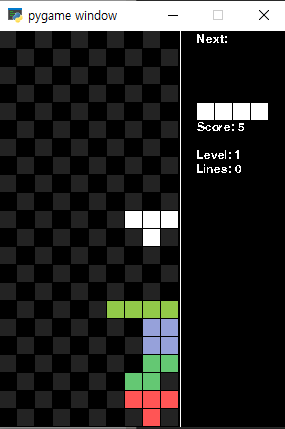

블럭들을 다시 단순화시켜 네모로도 학습시켜보고, 일자모양으로도 바꿔서 이것저것 해본 결과는 이렇다.
PPO는 빠르게 수렴하고 금방 학습되는 게 보이긴 했지만, 조금만 복잡해져도 탐색공간이 넓어져서 잘 안되는 것 같았다.

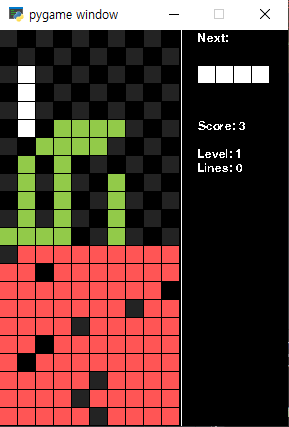
결론적으로는 위에서 말했던 DQN처럼 모든 공간을 탐색해서 값을 내주는 게 테트리스 해결에는 맞는 방법인 것 같다.
처음 해봐서 잘 모르는 게 많아 삽질을 많이 했는데 그걸 나름대로 적어보았다.
'AI | ML > Reinforcement Learning' 카테고리의 다른 글
| [RL] DQN(Deep Q-Network) 논문 리뷰 (0) | 2024.01.18 |
|---|---|
| [RL] Beginner Guide (3) | 2024.01.16 |
| [ML-Agent] Unity 게임을 gym.Env 환경으로 변경 (0) | 2021.09.03 |
| pyMARL 구조 분석 + COMA 코드 분석 (0) | 2021.08.23 |
| [Unity] ML-Agents 설치 및 테스트해보기 (2) | 2021.08.13 |