논문 소개
링크 : https://arxiv.org/pdf/1602.01783.pdf
github : https://github.com/ikostrikov/pytorch-a3c
Main Contributions
- Experience replay 기반 RL 대신, 비동기 병렬 방식을 이용한 새로운 패러다임 제시
- GPU 기반의 학습보다, 병렬 처리 기반 CPU 연산으로 학습 속도, 안정성 개선
1. Intro 요약
- Experience replay 기반의 RL은 메모리와 연산이 더 크고, off-policy여서 업데이트 과정도 필요
- 본 논문에서는 비동기 병렬 방식을 이용해 새로운 패러다임을 제시
- 프로세스에서 다양한 스펙트럼이 생기고, Q-Learning 과 같은 다양한 off-policy 알고리즘에서도 가능
- 기존 GPU를 많이 사용하는 알고리즘보다, multi-core CPU 연산으로도 효율적
2. Reinforce Learning Background
기초 지식
- Environment : 주어진 환경
- Agent : 환경 내에서 행동하는 주체
- State : Agent의 상태
- Action : Agent가 행동한 결과
- Policy : Agent가 취할 행동을 결정하는 방식, 알고리즘
- Value : State를 기반으로 결정한 값 (=Model이 예측한 값)
- Reward : Agent에게 돌려주는 보상
Value Function과 Policy Function 두 가지를 다 사용하는 경우도 있는데, 이는 Actor-Critic 모델이라 한다.
4. Asynchronous RL Frameworks
기본적으로 논문이 Asynchronous을 초점으로 여러 알고리즘을 실험한 것이므로 Actor-Critic 알고리즘을 이해해야 한다.
Actor-Critic 알고리즘에서 설명하는 Action, Reward 방식은 다음과 같다.

π(a|s) 는 state(=observation)가 주어졌을 때, 어떤 action을 취할 지 선택하는 Policy다.
δ는 TD(Temporal Differential) 기호로 미래 상태와 현재 상태의 차이값을 말한다.
Asynchronous Advantage Actor-Critic

Asynchronous Advantage Actor-Critic 알고리즘
기존 actor-critic에서 추가된 "advantage" 는 High Dimensional continuous control using generalized advantage 논문에서 GAE(Generalized Advantage Estimation)라고 쓰인 개념으로,
policy gradient 관점에서 bias를 줄여 학습의 variance를 줄일 수 있다고 한다.


논문에서는 λ=1로 설정하면, 아래와 같은 수식으로 볼 수 있다.

논문에서는 추가로, policy function이 sub-optimal로 빠지지 않도록 regularization을 추가해, 최종 policy loss는 다음과 같다.
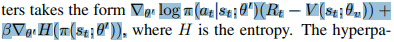
5. Experiments
- Code 분석
논문에서 병렬 처리를 이용해 코드 중복을 제거한 예시
torch.manual_seed(args.seed + rank)
위 코드를 이용해 각각의 seed를 주어 random 값의 생성 방식이 달라진다 (rank 는 process number)

논문에서 사용하는 Value Function과 Policy Function은 파라미터를 공유한다
Value Function, Policy Function (DNN) 코드
class ActorCritic(torch.nn.Module):
def __init__(self, num_inputs, action_space):
super(ActorCritic, self).__init__()
self.conv1 = nn.Conv2d(num_inputs, 32, 3, stride=2, padding=1)
self.conv2 = nn.Conv2d(32, 32, 3, stride=2, padding=1)
self.conv3 = nn.Conv2d(32, 32, 3, stride=2, padding=1)
self.conv4 = nn.Conv2d(32, 32, 3, stride=2, padding=1)
self.lstm = nn.LSTMCell(32 * 3 * 3, 256)
num_outputs = action_space.n
self.critic_linear = nn.Linear(256, 1)
self.actor_linear = nn.Linear(256, num_outputs)
# weight 초기화 부분
self.apply(weights_init)
self.actor_linear.weight.data = normalized_columns_initializer(
self.actor_linear.weight.data, 0.01)
self.actor_linear.bias.data.fill_(0)
self.critic_linear.weight.data = normalized_columns_initializer(
self.critic_linear.weight.data, 1.0)
self.critic_linear.bias.data.fill_(0)
self.lstm.bias_ih.data.fill_(0)
self.lstm.bias_hh.data.fill_(0)
self.train()
def forward(self, inputs):
inputs, (hx, cx) = inputs
x = F.elu(self.conv1(inputs))
x = F.elu(self.conv2(x))
x = F.elu(self.conv3(x))
x = F.elu(self.conv4(x))
x = x.view(-1, 32 * 3 * 3)
hx, cx = self.lstm(x, (hx, cx))
x = hx
return self.critic_linear(x), self.actor_linear(x), (hx, cx)
forward 함수 부분을 보면 같은 x를 공유한 뒤, 마지막에 달라지는 것을 볼 수 있다.
Value loss, Policy loss 코드
for step in range(args.num_steps):
episode_length += 1
value, logit, (hx, cx) = model((state.unsqueeze(0),(hx, cx)))
prob = F.softmax(logit, dim=-1)
log_prob = F.log_softmax(logit, dim=-1)
entropy = -(log_prob * prob).sum(1, keepdim=True)
entropies.append(entropy)
action = prob.multinomial(num_samples=1).detach()
log_prob = log_prob.gather(1, action)
state, reward, done, _ = env.step(action.numpy())
done = done or episode_length >= args.max_episode_length
reward = max(min(reward, 1), -1)
with lock:
counter.value += 1
if done:
episode_length = 0
state = env.reset()
state = torch.from_numpy(state)
values.append(value)
log_probs.append(log_prob)
rewards.append(reward)
if done:
break
R = torch.zeros(1, 1)
if not done:
value, _, _ = model((state.unsqueeze(0), (hx, cx)))
R = value.detach()
values.append(R)
policy_loss = 0
value_loss = 0
gae = torch.zeros(1, 1)
for i in reversed(range(len(rewards))):
R = rewards[i] + args.gamma * R
advantage = R - values[i]
value_loss = value_loss + 0.5 * advantage.pow(2)
# Generalized Advantage Estimation
delta_t = rewards[i] + args.gamma * values[i + 1] - values[i]
gae = gae * args.gamma * args.gae_lambda + delta_t
policy_loss = policy_loss - log_probs[i] * gae.detach() - args.entropy_coef * entropies[i]
'AI | ML > Reinforcement Learning' 카테고리의 다른 글
| [RL] stable-baselines3 학습 커스터마이징해보기 (0) | 2021.07.30 |
|---|---|
| [RL] Windows 환경에서 Ray 설치 및 실행하기 (0) | 2021.07.29 |
| [RL] stable-baselines3 모델 학습, 불러오기 (0) | 2021.07.13 |
| [RL] 강화학습 모델 라이브러리 stable-baselines3 사용해보기 (0) | 2021.07.13 |
| [gym] NotImplementedError 에러 해결방법 (0) | 2021.06.10 |