Abstract
- Policy Gradient 알고리즘을 이용한 RL 기반의 attention agent로 Backbone 네트워크 제안
- 학습된 적 없는 데이터에도 학습이 가능한 범용적인 reward function 설계
Introduction
- 딥러닝 알고리즘이 데이터에 의존적임에 따라 라벨링의 중요성이 언급되지만, 데이터가 클수록 준비해야하는 양도 많다보니 제약이 많다 → few-shot learning 연구의 시작점 언급
- few-shot learning 접근법 소개
- Model Initialization 방법
- gradient descent 같은 방법으로 모델 파라미터를 업데이트하며 test단계를 아우르는 표현방식을 찾는 방법
- metric-base 기반 방법
- backbone network의 global embedding을 기반으로 하는 방식
- Model Initialization 방법
- few-shot learning 접근법 소개
- 위의 방법들이 잘 되긴 했는데, 이미지에서는 배경이 산만할수록 예민해진다는 단점 지적
- attention 기반 방법 소개
- 배경 : 공간 정보를 최대한 활용하기 위해 attention 기반의 설계
- 장점 : semantic-guided attention 모델은 특징을 잘 캐치할 뿐만 아니라 특징 연관성도 찾는 게 가능
- 단점 : meta-learner를 설계하는데에 너무 초점을 맞춘다는 지적
- 위의 단점들을 보완하는 RAP(reinforced attention policy) 모델을 제안
- 특히, 보조 agent는 피쳐맵을 강화할지 무시할지 결정하는 attention map을 계산하는 backbone 네트워크를 갖추도록 설계
RAP(reinforced attention policy) 소개
- 장점
- backbone network 을 잘 설계해서 meta-learner에게 더 결정적인 임베딩을 생성시켜줌
- MDP를 이용한 feature extraction
- agent가 실시간 피드백으로 최적화됨
- reward function이 기가 막혀서 일반화가 잘 되도록 설계
- 방법(How to?)

출처 : 카카오브레인 - few shot learning은 보통 Query, Support 구조로 나뉘어 feature embedding을 진행하며 학습된다.
이 부분을 MDP를 이용해서 policy module을 구성하여 meta-learner로부터의 피드백을 reward로 둔다면,
action은 보상을 큰 방향으로 결정하면 됨
- few shot learning은 보통 Query, Support 구조로 나뉘어 feature embedding을 진행하며 학습된다.
-
- 이를 시간 t로 둔다면 마지막 예측으로 $Yˆ_{q,t}$가 생기는데, 이 때 중요한 건
단순한 수정만으로도 meta-learner를 설계할 필요가 없어지고, 다른 few shot learning baseline처럼 임베딩이 된다
- 이를 시간 t로 둔다면 마지막 예측으로 $Yˆ_{q,t}$가 생기는데, 이 때 중요한 건
- Main Contributions
- meta-learner 설계의 수고를 덜고, 어텐션의 효과를 가진다
- RL을 이용한 attention 매커니즘 도입
2.Related Works - 생략
3. Methodology
3.1 Problem Statement
번외 - 강화학습 간단한 설명
강화학습에서는 agent, env, state, action 등의 용어가 쓰인다.
요약해서 설명하면 어떤 환경(Environment)에 놓여있는 객체(Agent)가 있고,
environment로부터 정보를 관측(observation = state)하여 행동(action)한다.
행동에 대한 보상(reward)로 행동이 강화(reinforcement)된다.

State
논문에서는 state로 Input인 W x H x 3 의 이미지, 그리고 CNN을 통해 embedding feature는 S x E x 1 형태를 지닌다.
여기서 S, E는 FC layer로 데이터셋의 클래스 숫자나 CNN 모델별로 변한다.
Action
피쳐맵에서 어느 부분에 어텐션을 줄 지 정하는 액션은 h x w x c 의 형태를 지닌다. 그림 3에서 가져온 예시로,
policy network에서 h x w x 1 형태의 a^v_t를 reshape하고, 복제해서 피쳐맵과 같은 h x w x c 형태로 만들어
element-wise 곱으로 어텐션을 결정한다.
Rewards
RAP의 목적이 정보가 되는 영역을 판단해 어텐션을 주는게 목적이였다고 한다. 그래서 선택지 중 하나가 고정 데이터에 대해서 얼마나 성능을 보이는지를 판단하는 것이였고, 이는 validation set에서의 성능을 말하는 것이 된다. 따라서 reward function은 t-step 당시의 validation loss에 $\alpha$라는 계수를 곱한 값으로 주었다.
전반적인 구조 설명
(a)는 흔히 쓰이는 기초적인 모델인데, RAP에서 제안하는 model은 (b)의 그림과 같다.
강화학습에서 쓰이는 state, action, reward 구조로 만들기 위해 학습하는 이미지 단계를 시간순인 step으로 구분하고, CNN의 feature map을 state policy network에서 피쳐맵을 입력받아 action을 결정하도록 만들고, 이 action으로 나오는 feature를 기존 backbone에 곱하는 attention 구조를 가지며 T 스텝까지 반복한다.
위의 구조로 하면 RAP agent가 피쳐맵의 어느 부분이 더 정보가 되는지 판단하여 만든다고 한다.
3.2 Policy Design
h x w x 1 의 아웃풋을 갖는 vector u_t와 만들어내는 policy function을 $g(s_t| \theta_p)$ 라고 하고, g를 기반으로 분포하는 $\pi$함수가 있다고 가정하면, $a^v_t$는 h x w x 1 의 공간 내에서 선택될 것이다.
다시 위의 그림을 보면, $s_i$ 로 이미지가 주어졌을 때, 보통의 conv block을 거치면 pooling도 진행되서 최종적으로 1차원인 I 채널의 벡터로 변경된다. 그리고 벡터 I는 이전 상태의 $I^F_t$와 콘캣하여 $I_t$로 만들수 있고, $I_t$는 FC layer를 거치면 $u_t$가 된다. 이후 $a_t$는 위에 설명한 것과 같다. 핵심은 보조 알고리즘이 너무 관여하는 것을 막기 위해, 1st conv block을 얕게 설정했다고 한다.
3.3 Policy Training
위의 내용을 쭉 풀어보면, 학습 가능한 파라미터는 $\theta_b, \theta_p$로 b는 백본, p는 policy network다. Policy Network의 목적은 보상을 최대화하는 것으로, 논문에서는 REINFORCE 논문의 알고리즘을 적용하였다.
REINFORCE 알고리즘의 핵심은 Monte-Carlo Policy Gradient로,
Monte-Carlo 가정은 샘플을 무작위로 하다보면 분포를 예상할 수 있을 것이라는 가정으로
무작위로 샘플링하면서 reward를 받고, 그 reward를 기반으로 policy를 업데이트하는 것을 의미한다.
논문에서는 수식을 잘 보면 reward가 0이라면 나머지도 자연히 0이 되기에 수식 자체는 문제가 되지 않는데,
강화학습 시에 train data로 인해 validation loss가 진행이 잘 안되서, 정확도를 깎아먹지 않을까 걱정했다고 한다.
이를 피하는 방법은 train loss도 같이 넣어서, 최종 손실 함수는 다음과 같이 구성했다고 한다.
이렇게 했을 때 train loss의 장점으로 backbone network의 기본 성능을 보장해주고,
rein loss의 장점으로 validation 데이터로부터 어느 영역을 볼 지 attention이 진행된다고 한다.
4. Experiments
이렇게 만들어진 모델은 주로 few-shot learning에 테스트했지만, few-shot learning에 국한된 게 아니라는 걸 확인하기 위해 classification 데이터셋인 CIFAR-10/100, STL-10 에도 테스트를 진행했다.
augmentation으로는 흔히 쓰이는 random crop, flip 등을 진행 augmentation하였고, optimizer는 Adam,
validation에 대한 정보는 validation accuracy가 제일 높은 걸 기준으로 진행하였다.
4.2 Few-Shot learning
논문에서는 MAML, ProtoNet이라는 few-shot learning 논문에 RAP module을 적용하였다. 그 결과는 아래와 같다.
meta-learning이 잘 되었는지 네트워크가 얕고, shot이 작을수록 성능 향상이 많이 되는 것을 볼 수 있다.
network가 깊을수록 성능 향상이 미미한 것으로 보이는데, 이 부분에 대한 설명은 보이지 않는다.
하지만 내 생각으론 conv가 너무 얕아서 특징 추출이 잘 안 되었을 때 attention으로 보완이 된다는 것을 말해주는 것 같다.
4.3 Image Classification
위의 언급한대로 few-shot learning에만 국한된게 아니라 Classification에도 유효한 지 테스트한 결과로
전반적으로 성능이 향상되는 것으로 보아 RAP 모듈이 특징 추출에 전반적으로 도움이 된다는 것을 볼 수 있다.
4.4 Analysis
읽으면서 말이 안된다고 생각했던 부분을 저자도 같은 생각을 했던 것 같다.
엄연히 train data 만으로 validation을 평가했어야 했는데, 논문에서는 validation에서 생긴 loss도 쓰고 있기 때문이다.
따라서 마찬가지로 baseline 모델들도 train + val 로스로 진행해보았다.
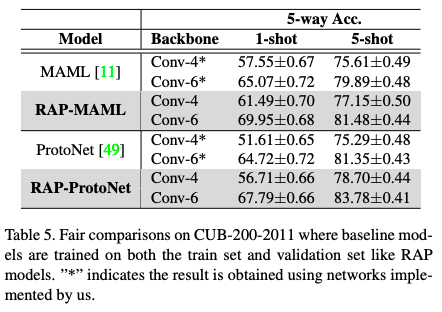
왼쪽은 train만 이용한 예시, 오른쪽은 train+val 같이 진행한 결과로
기존의 다른 모델들도 성능이 오르는 것은 볼 수 있지만, RAP가 더 정확도가 높은 것을 볼 수 있다.
Attention Design
논문에서는 설계된 Attention module인 RAP가 기존 CNN 기반의 attention module인
CBAM, SENet과 얼마나 다른지도 테스트를 진행하였다.
CBAM, SENet과 비교했을 때도 더 나은 attention 성능을 갖는 것을 볼 수 있다.
5. Conclusion
- RL을 이용해 attention 구조를 만들어 few-shot learning 분야에 적용한 첫 시도
- 만들어낸 RAP 모듈이 few-shot learning 분야에서 기존 논문들보다 성공적으로 특징을 분류함
- RL의 recurrent한 구조가 경험적으로 더 나은 attention을 제공해낼 수 있다는 점이 제일 인상깊음