728x90
지난 포스터에서 Windows C++ ONNX 환경 설정을 하였습니다.
이번 시간에는 ONNX를 환경 테스트 하는 방법에 대해 설명하겠습니다.
지난 시간에 https://github.com/microsoft/onnxruntime 사이트에서 onnx 환경을 다운받았는데요,
onnx 환경이 제대로 작동하는지 확인하기 위해, 아래 경로의 사이트에서 cpp 예제 파일을 실행해봅시다.
#include <assert.h>
#include <vector>
#include <onnxruntime_cxx_api.h>
int main(int argc, char* argv[]) {
//*************************************************************************
// initialize enviroment...one enviroment per process
// enviroment maintains thread pools and other state info
Ort::Env env(ORT_LOGGING_LEVEL_WARNING, "test");
// initialize session options if needed
Ort::SessionOptions session_options;
session_options.SetIntraOpNumThreads(1);
// If onnxruntime.dll is built with CUDA enabled, we can uncomment out this line to use CUDA for this
// session (we also need to include cuda_provider_factory.h above which defines it)
// #include "cuda_provider_factory.h"
// OrtSessionOptionsAppendExecutionProvider_CUDA(session_options, 1);
// Sets graph optimization level
// Available levels are
// ORT_DISABLE_ALL -> To disable all optimizations
// ORT_ENABLE_BASIC -> To enable basic optimizations (Such as redundant node removals)
// ORT_ENABLE_EXTENDED -> To enable extended optimizations (Includes level 1 + more complex optimizations like node fusions)
// ORT_ENABLE_ALL -> To Enable All possible opitmizations
session_options.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_EXTENDED);
//*************************************************************************
// create session and load model into memory
// using squeezenet version 1.3
// URL = https://github.com/onnx/models/tree/master/squeezenet
#ifdef _WIN32
const wchar_t* model_path = L"squeezenet.onnx";
#else
const char* model_path = "squeezenet.onnx";
#endif
printf("Using Onnxruntime C++ API\n");
Ort::Session session(env, model_path, session_options);
//*************************************************************************
// print model input layer (node names, types, shape etc.)
Ort::AllocatorWithDefaultOptions allocator;
// print number of model input nodes
size_t num_input_nodes = session.GetInputCount();
std::vector<const char*> input_node_names(num_input_nodes);
std::vector<int64_t> input_node_dims; // simplify... this model has only 1 input node {1, 3, 224, 224}.
// Otherwise need vector<vector<>>
printf("Number of inputs = %zu\n", num_input_nodes);
// iterate over all input nodes
for (int i = 0; i < num_input_nodes; i++) {
// print input node names
char* input_name = session.GetInputName(i, allocator);
printf("Input %d : name=%s\n", i, input_name);
input_node_names[i] = input_name;
// print input node types
Ort::TypeInfo type_info = session.GetInputTypeInfo(i);
auto tensor_info = type_info.GetTensorTypeAndShapeInfo();
ONNXTensorElementDataType type = tensor_info.GetElementType();
printf("Input %d : type=%d\n", i, type);
// print input shapes/dims
input_node_dims = tensor_info.GetShape();
printf("Input %d : num_dims=%zu\n", i, input_node_dims.size());
for (int j = 0; j < input_node_dims.size(); j++)
printf("Input %d : dim %d=%jd\n", i, j, input_node_dims[j]);
}
// Results should be...
// Number of inputs = 1
// Input 0 : name = data_0
// Input 0 : type = 1
// Input 0 : num_dims = 4
// Input 0 : dim 0 = 1
// Input 0 : dim 1 = 3
// Input 0 : dim 2 = 224
// Input 0 : dim 3 = 224
//*************************************************************************
// Similar operations to get output node information.
// Use OrtSessionGetOutputCount(), OrtSessionGetOutputName()
// OrtSessionGetOutputTypeInfo() as shown above.
//*************************************************************************
// Score the model using sample data, and inspect values
size_t input_tensor_size = 224 * 224 * 3; // simplify ... using known dim values to calculate size
// use OrtGetTensorShapeElementCount() to get official size!
std::vector<float> input_tensor_values(input_tensor_size);
std::vector<const char*> output_node_names = { "softmaxout_1" };
// initialize input data with values in [0.0, 1.0]
for (unsigned int i = 0; i < input_tensor_size; i++)
input_tensor_values[i] = (float)i / (input_tensor_size + 1);
// create input tensor object from data values
auto memory_info = Ort::MemoryInfo::CreateCpu(OrtArenaAllocator, OrtMemTypeDefault);
Ort::Value input_tensor = Ort::Value::CreateTensor<float>(memory_info, input_tensor_values.data(), input_tensor_size, input_node_dims.data(), 4);
assert(input_tensor.IsTensor());
// score model & input tensor, get back output tensor
auto output_tensors = session.Run(Ort::RunOptions{ nullptr }, input_node_names.data(), &input_tensor, 1, output_node_names.data(), 1);
assert(output_tensors.size() == 1 && output_tensors.front().IsTensor());
// Get pointer to output tensor float values
float* floatarr = output_tensors.front().GetTensorMutableData<float>();
assert(abs(floatarr[0] - 0.000045) < 1e-6);
// score the model, and print scores for first 5 classes
for (int i = 0; i < 5; i++)
printf("Score for class [%d] = %f\n", i, floatarr[i]);
// Results should be as below...
// Score for class[0] = 0.000045
// Score for class[1] = 0.003846
// Score for class[2] = 0.000125
// Score for class[3] = 0.001180
// Score for class[4] = 0.001317
printf("Done!\n");
return 0;
( 출처 :
실제로 실행해보면, squeezenet 파일이 없을 뿐더러, 빨간 줄이 떠서 실행이 되지 않는 경우가 생기는데, 아래의 onnx 파일을 받으시고, 소스코드 내의 파일이름을 변경해주시면 됩니다.
그래도 소스코드를 보시면 여전히 빨간 줄이 생기는 것을 볼 수 있는데 소스코드 변경이 필요합니다.
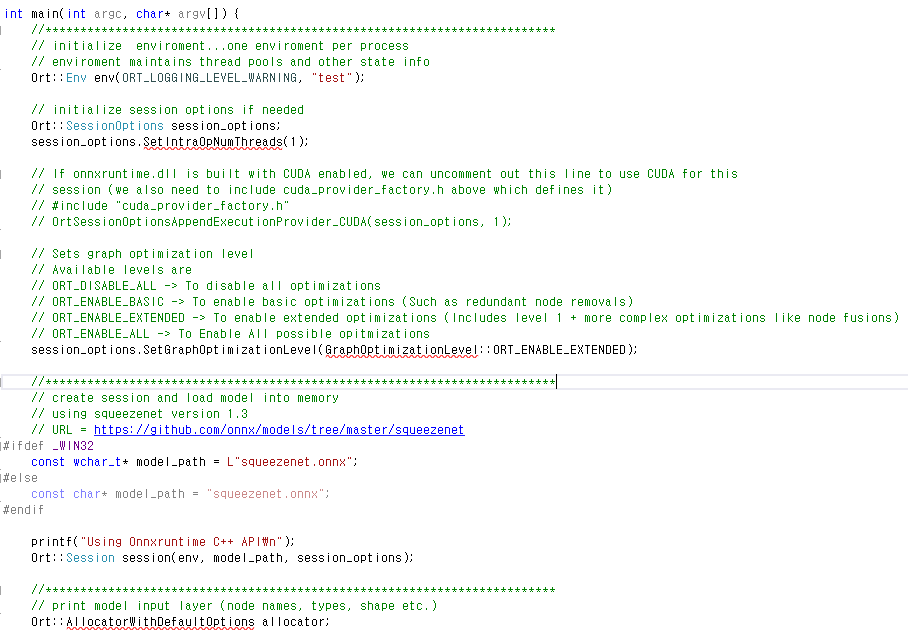
메인문 안에서 아래와 같이 소스코드를 변경하면 빨간 줄이 사라지게 됩니다.
Ort::Env env(ORT_LOGGING_LEVEL_WARNING, "test");
Ort::SessionOptions session_options;
session_options.SetThreadPoolSize(1);
session_options.SetGraphOptimizationLevel(1);
#ifdef _WIN32
const wchar_t* model_path = L"squeezenet1.1.onnx";
#else
const char* model_path = "squeezenet1.1.onnx";
#endif
printf("Using Onnxruntime C++ API\n");
Ort::Session session(env, model_path, session_options);
Ort::Allocator allocator = Ort::Allocator::CreateDefault();
size_t num_input_nodes = session.GetInputCount();
std::vector<const char*> input_node_names(num_input_nodes);
std::vector<int64_t> input_node_dims;
// iterate over all input nodes
for (int i = 0; i < num_input_nodes; i++) {
// print input node names
char* input_name = session.GetInputName(i, allocator);
input_node_names[i] = input_name;
// print input node types
Ort::TypeInfo type_info = session.GetInputTypeInfo(i);
auto tensor_info = type_info.GetTensorTypeAndShapeInfo();
// print input shapes/dims
input_node_dims = tensor_info.GetShape();
}
size_t input_tensor_size = 224 * 224 * 3;
std::vector<float> input_tensor_values(input_tensor_size);
std::vector<const char*> output_node_names = { "squeezenet0_flatten0_reshape0" };
for (unsigned int i = 0; i < input_tensor_size; i++)
input_tensor_values[i] = (float)i / (input_tensor_size + 1);
Ort::AllocatorInfo allocator_info = Ort::AllocatorInfo::CreateCpu(OrtArenaAllocator, OrtMemTypeDefault);
Ort::Value input_tensor = Ort::Value::CreateTensor<float>(allocator_info, input_tensor_values.data(), input_tensor_size, input_node_dims.data(), 4);
assert(input_tensor.IsTensor());
auto output_tensors = session.Run(Ort::RunOptions{ nullptr }, input_node_names.data(), &input_tensor, 1, output_node_names.data(), 1);
assert(output_tensors.size() == 1 && output_tensors.front().IsTensor());
float* floatarr = output_tensors.front().GetTensorMutableData<float>();
for (int i = 0; i < 5; i++)
printf("Score for class [%d] = %f\n", i, floatarr[i]);
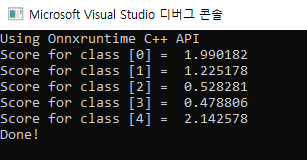
실행했을 때, 결과가 아래와 같이 나와야 합니다.
728x90
'AI | ML > AI 개발 | CUDA' 카테고리의 다른 글
| [CUDA] 윈도우 환경에서 CUDA 버전 변경 (0) | 2021.07.09 |
|---|---|
| [CUDA] CUDA 드라이버 호환 확인 (0) | 2020.12.21 |
| [TensorRT] Window 환경에서 PyTorch로 TensorRT 사용하기 (4) | 2019.10.07 |
| Window C++ ONNX 환경 실행 (0) | 2019.09.24 |
| Window C++ ONNX 환경 구축 (0) | 2019.09.24 |