TL;DR 3줄요약
파이썬은 GIL으로 인해 쓰레드를 사용하는 데 제약이 있다.
Multiprocessing이냐 multi thread냐는 상황에 따라 다르다.
병렬처리에서는 for문 구조를 줄이는게 핵심이다.
데이터셋 전처리 작업으로 코딩하는 와중에, 시간이 너무 오래 걸려서 파이썬 병렬처리에 관하여 공부를 많이 했다.
새롭게 알게 된 점은 파이썬에서는 GIL(Global Interpreter Lock) 이라고 하여,
다른 언어들과 다르게 물리적으로는 1프로세스에 1개의 쓰레드만 사용할 수 있다.
이에 대해선 파이썬을 개발한 귀도 반 로섬이 의도적으로 설계한 것이라고 한다.
I’d welcome a set of patches into Py3k only if the performance for a single-threaded program (and for a multi-threaded but I/O-bound program) does not decrease.
단일 thread 프로그램에서의 성능을 저하시키지 않고 GIL의 문제점을 개선할 수 있다면, 나는 그 개선안을 기꺼이 받아들일 것이다.
이 말을 그림으로 이해하자면 아래 그림과 같은데, 자세한 설명은 그림 하단의 출처를 참고하면 된다.
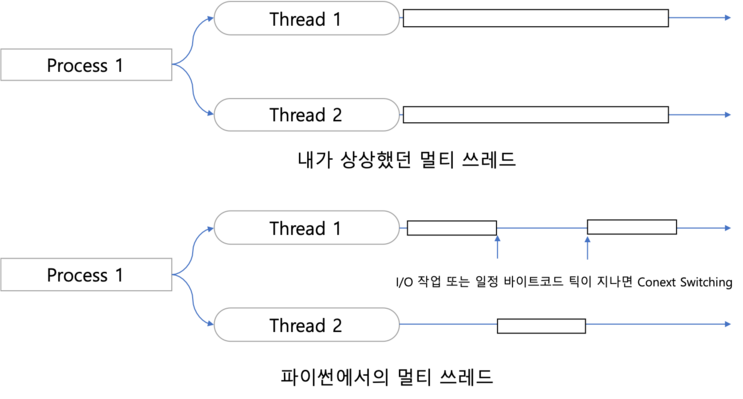
그러면 위의 그림을 보고 드는 이런 생각이 들 수도 있다.
병렬처리에는 Thread도 있고, Process도 있는데
저렇게 Thread가 자원을 나눠 쓰는 방식이면 파이썬에서는 무조건 Process쓰는게 좋은거 아니야?
그럼 Thread는 언제 쓰는거야?
Multi-Process와 Multi-Thread 차이점은 여러 가지가 있지만, 내 생각은 상황에 따라 다른 것 같다.
그 기준을 잡자면
- 프로세스 간 통신인지, 프로세스 내 통신
- I/O에 대해서 병목현상이 있는 경우
- 컴퓨터의 자원 여유 상황
(그 이유에 대한 설명은 이전 포스팅에 적어놓았다.)
나의 경우에는 MultiProcessing을 이용해서 속도 개선을 시켰다.
초기의 코드는 다음과 같은데, 1개의 dataset인 15000개 파일을 읽어들여 전처리한 뒤 1개의 파일로 저장하는 방식이다
def label_parse(path):
img_exts = ['.jpg', '.png', '.jpeg']
label_exts = ['.txt', '.xml', '.json']
dataList = glob.glob(path+'/**')
imgList = list()
labelList = list()
imgList = [x for x in dataList if os.path.splitext(x)[1] in img_exts]
labelList = [x for x in dataList if os.path.splitext(x)[1] in label_exts]
id_dict = dict()
anno_id = 0
COCO_img_list = list()
COCO_anno_list = list()
### for문을 이용한 순차적 진행 방식
for idx, imgpath in enumerate(imgList):
# 대충 전처리하는 내용
imgname = os.path.splitext(imgpath)[0]
imgname_path = '/'.join(imgname.split('/')[:-1])
imgname = imgname.split('/')[-1].split('_')[0]
imgname = imgname_path+'/'+ imgname
# print(imgname)
if os.path.exists(imgname + '.txt'):
img_info, anno_info, anno_id = txt_label(imgname, idx, anno_id, category_list)
elif os.path.exists(imgname + '.json'):
img_info, anno_info, anno_id = json_label(imgname, idx, anno_id, category_list)
elif os.path.exists(imgname + '.xml'):
img_info, anno_info, anno_id = xml_label(imgname, idx, anno_id, category_list)
else:
raise("Can't find annotation")
COCO_img_list.append(img_info)
COCO_anno_list.extend(anno_info)
categories = list()
for idx, category in enumerate(category_list):
categories.append({'id' : idx +1, 'name': category, 'supercategory': "Tank"})
COCO_format = dict()
COCO_format['info'] = {
}
COCO_format['images'] = COCO_img_list
COCO_format['annotations'] = COCO_anno_list
COCO_format['licenses'] = {}
COCO_format['categories'] = categories
return COCO_format
아래는 multiprocessing으로 변환한 결과로,
순차적인 방식에서 병렬처리로 변경할 때 핵심은, for문 구조를 최대한 줄이는 것이다.
나름의 for문을 줄여본 나의 코드는 다음과 같다.
from multiprocessing import Pool, Process, Manager
import multiprocessing
import os, glob, time
def label_directory(path):
img_exts = ['.jpg', '.png', '.jpeg']
label_exts = ['.txt', '.xml', '.json']
dataList = glob.glob(path+'/**')
imgList = list()
labelList = list()
imgList = [x for x in dataList if os.path.splitext(x)[1] in img_exts]
labelList = [x for x in dataList if os.path.splitext(x)[1] in label_exts]
id_dict = dict()
anno_id = 0
COCO_img_list = Manager().list()
COCO_anno_list = Manager().list()
pool = Pool(multiprocessing.cpu_count())
pool.starmap(label_file, [(imgpath, COCO_img_list, COCO_anno_list) for imgpath in imgList])
pool.close()
pool.join()
categories = list()
for idx, category in enumerate(category_list):
categories.append({'id' : idx +1, 'name': category, 'supercategory': "None"})
COCO_format = dict()
COCO_format['info'] = {}
COCO_format['images'] = list(COCO_img_list)
COCO_format['annotations'] = list(COCO_anno_list)
COCO_format['licenses'] = {}
COCO_format['categories'] = categories
return COCO_format
def label_file(imgpath, COCO_img_list, COCO_anno_list):
imgname = os.path.splitext(imgpath)[0]
imgname_path = '/'.join(imgname.split('/')[:-1])
imgname = imgname.split('/')[-1].split('_')[0]
imgname = imgname_path+'/'+ imgname
# print(imgname)
label_exts = ['.txt', '.xml', '.json']
# print("PID : " + str(os.getpid()) + "\t path : ", imgpath)
if os.path.exists(imgname + '.txt'):
img_info, anno_info = txt_label(imgname)
elif os.path.exists(imgname + '.json'):
img_info, anno_info = json_label(imgname)
elif os.path.exists(imgname + '.xml'):
img_info, anno_info = xml_label(imgname)
else:
raise("Can't find annotation")
COCO_img_list.append(img_info)
COCO_anno_list.extend(anno_info)
if __name__=="__main__":
folder_path = '/input/dataset/path'
# Train
start_time = time.time()
train_path = os.path.join(folder_path, 'train')
COCO_train = label_directory(train_path)
output = open('train.json', 'w')
output.write(json_dumps(COCO_train))
output.close()
# Val
val_path = os.path.join(folder_path, 'val')
COCO_val = label_directory(val_path)
output = open('val.json', 'w')
output.write(json_dumps(COCO_val))
output.close()
print("Time : ", time.time() - start_time)


htop을 이용하여 cpu 사용량을 확인해본 결과 cpu가 불타오르는 것을 볼 수 있었다.
그리고, 그 실행결과는 데이터가 대략 15000개 기준으로
cpu 코어 20개를 활용하여서 823초 걸리던 과정이 69초로 줄어든 모습을 볼 수 있었다.

[참고]
https://dgkim5360.tistory.com/entry/understanding-the-global-interpreter-lock-of-cpython [개발새발로그]
zzaebok.github.io/python/python-multiprocessing/
[GIL에 관한 설명]
'Programming Language > Python' 카테고리의 다른 글
| [Python] 사전(dict)형 정렬하기 (0) | 2021.03.21 |
|---|---|
| [Python] Albumentations를 이용한 데이터 증강 및 실험 (1) | 2021.03.18 |
| [Python] GIL 관련 OS, 컴퓨터구조가 중요한 이유 (2) | 2021.02.18 |
| 역세권 청년주택 자동 이메일 알람 설정 (0) | 2021.01.10 |
| [Python] Matplotlib 사용법 (0) | 2020.12.15 |