최근에 논문을 너무 안 읽은 것 같아 논문을 읽어보려고 하다가 어텐션이 많이 들어가서 파악이 잘 안 됐다.
트랜스포머가 좋은 논문이라고 해서 많이 듣기는 했는데
이것부터 읽어보지 않으면 다음 논문을 읽어볼 수 없을 것 같아 트랜스포머를 읽어보았다.
그동안 트랜스포머에 대해 간략하게 들어보면서 내가 궁금했던 것은 이렇다.
- NLP 에서 Transformer 가 이전과의 차이점이 무엇인지?
- 학습 구조
- 트랜스포머 내에서 Query, Key, Value 라는 단어가 왜 쓰였는지?
그리고 아래는 내가 트랜스포머 논문을 읽으면서 간략하게 요약해보면서 적었다.
1. Introduction
- RNN 모델 특성 상 길어질수록 메모리의 제약이 생김
- 이 문제를 해결하기 위해 분해 트릭이나 조건부 연산 같은 연구가 있었고, 후자가 더 성능이 좋았지만 기초적으로 순차적 연산이라는 제약이 여전히 남아있었음
- 순차적 길이에 상관없이 시퀀스 모델링이 가능하도록 하는 어텐션 메커니즘 개발하여 Transformer 라 이름 붙임
2. Background 생략
3. Model Architecture
- 최신 논문들은 Encoder-Decoder 구조로 인코더는 X(

3.1 Encoder and Decoder Stacks
- Encoder
- 한 개의 Encoder 안에 2개의 Sub-layer 가 존재하고 Residual-connection을 적용하여 6개의 Encoder가 반복
- 첫번째 sub-layer는 multi-head self-attention 구조
- 두번째 sub-layer는 position-wise FC layer
- Decoder
- 한 개의 Decoder 안에 3개의 Sub-layer가 존재하지만, 2개의 Sub-layer는 Encoder와 동일, Residual-Connection 적용
- 나머지 1개의 레이어는 Encoder 로부터 들어온 입력에 multi-head attention 적용
- 이후 상태가 아닌 이전 상태에만 영향을 받도록 Decoder를 수정
3.2 Attention
- Query, Key, Value라는 벡터를 통해 Output 을 내는 구조를 지님
- Value 는 가중치들의 합을 낼 때 사용되며, Value는 Key Vector에 대응되는 Query를 통해 계산됨
3.2.1 Scaled Dot-Product Attention
- 입력을 Q(Query), K(Key), V(Value)로 구성
- K와 Q는 D_k 차원 , V는 D_v 차원 으로 구성
- Q를 모든 K에 대해 Dot-product 로 내적한 뒤,
value에 대한 가중치를 계산 - 함수 수식
- 가장 많이 쓰이는 어텐션 함수는 additive function, dot-product function
- additive function은 네트워크에서 진행될 때 기존 히든 레이어와 양립성을 계산 (resNet 참조)
- dot-product(내적) 함수는 행렬 연산에서 빠르고, 최적화가 가능
- additive attention이 dot product attention보다 뛰어나기 때문에,
- additive attention이 dot product attention보다 뛰어나기 때문에,
- root 쓴 이유
3.2.2 Multi-Head Attention
- single attention을 사용하지 않고, 여러 개로 어텐션하는게 각각 다르게 선형 투영(projection)하는 것이 더 이득이 됐기 때문에 Q, K, V 라는 벡터로 투영함
- 다른 위치에서 다른 표현의 하위 공간의 정보를 공동으로 처리 가능
- single-attention으로 한다면, 평균화되면서 불가능 (Q == K == V 처럼 됨)
- 병렬처리를 위해 h=8 로 놓음 (PC 개수만큼 H값을 할당하여 병렬 연산 가능)
- Attention 적용
- Encoder-Decoder 레이어에서 query는 이전 Decoder 레이어로부터 넘어오는데, Key, Value는 Encoder의 결과로부터 넘어와 각 디코더들은 인풋 시퀀스가 어텐션되어 들어감
- Encoder 는 Self-Attention 이 있으므로 각 Encoder layer별로 어텐션이 각각 다를 수 있음
- 유사하게 Decoder도 Self-Attention이 있으므로 어텐션이 각각 다를 수 있음
- RNN처럼 이전 상태가 유입되진 않게 하기 위해 scaled dot-product attention에서 softmax 함수의 입력 Value를
3.3 Position-wise Feed-Forward Network(FFN)
- 단순한 선형 연산을 2번 적용
- 활성화 함수는 ReLU 사용
- FC Layer 적용 방법 중 하나로, 1x1 Conv를 사용할 수도 있음
- Input, Output은 512 채널, 중간 레이어는 2048 채널(512 → 2048 → 512)

3.4 Word Embedding
- 선형 변환 후, softmax를 적용하였고, 임베딩 과정 중,
3.5 Positional Encoding
- Transformer는 CNN, RNN이 없으므로, 시퀀스의 순서를 활용하기 위해 포지션 정보를 부여
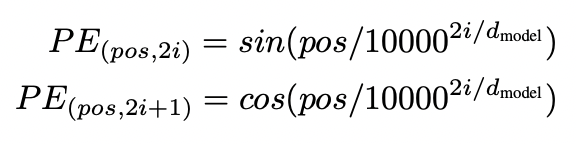
4. Why Self-Attention
- 1 Sequence Length mapping에 대해 RNN, CNN도 있는데 왜 attention을 썼는지 3가지 요구조건으로 설명
- 레이어 별 계산 복잡도
- 병렬화 할 수 있는 연산량
- 긴 범위의 종속성

- RNN은 Sequence Length에 따라 순차적으로 연산이 필요한데 비해, Self-Attention은 길이와 상관없이 한번의 연산이면 될 뿐더러, 계산복잡도도 낮음 (일반적으로 n < d, n : 시퀀스 길이, d : 네트워크 차원 )
- 연산 성능 개선을 위해 n을 r개로 분할한다면, 연산 속도도 O(n/r) 개선 가능
- CNN의 경우는 커널 개수에 따라 달라짐
5. Training
- P100 GPU x 8 개로 학습시켰는데 base model의 경우, 100,000 스텝에 12시간 걸림
- Optimizer 는 Adam으로,
- 초기 warmup_step으로 4000을 지정
- Label Smoothing 적용
- Encoder, Decoder 에서 embedding 합치는 sub-layer 부분 (FC Layer)에서 Dropout =0.1 로 적용
6. Result - 생략
7. Conclusion
- RNN 계열이 아닌 어텐션 기반의 번역 모델인 Transformer 발표
- RNN, CNN 계열보다 성능 우수
Attention 예시
리뷰 - 개인적인 궁금증 풀어보기
- NLP 에서 Transformer 가 어떻게 성능이 확 변하게 되었는지?
- 왜 Q, K, V 라는 단어가 쓰였는지
개인적으로 생각하는 Transformer의 성능 변화 요인
대략적인 요약을 하며 이해해보고, 내가 이해할 수 있는 방법으로 호기심을 풀어보려고 해보았다.
먼저 트랜스포머가 어떻게 성능을 끌어올렸고, 왜 인용이 많이 되는지에 대해 생각해봤는데,
당연히 성능이 따라주었기 때문에 인기가 높을 수밖에 없기도 했겠지만, 개인적으로는 문제 접근방식이 신선했다.
그 이유로는 기존 RNN에서 반복적으로(Recurrent) 진행하면서 생기는 시퀀스 간 긴 종속성 문제를 어텐션으로 풀어냈다는 점,
어텐션 속에서도 기존의 single-attention 보다 multi-head attention 으로
각각 Query, Key, Value 라는 작은 망으로 분리하여 학습시킨 점,
병렬처리를 가능하게 해서 Batch Normalization 효과를 더 크게 작용시킬 수 있었던 것이 성능에는 얼마나 큰진 모르겠지만 한 요소가 되었을 것 같았고, 기존 RNN으로 했으면 길었을 학습시간이 줄어든 것도 인상깊었다.
왜 Query, Key, Value 라는 단어가 쓰였을까?
보통 Query, Key, Value 는 DB에서 많이 쓰는 말로,
DB는 질의어(Query)에 따라 DB에서는 해당하는 Key 값을 검색하고, Key에 해당하는 Value를 반환한다.
Multi-Head Attention 의 과정을 보면 내적(dot-product)은 0~1 사이의 값을 갖는데,
흔히 코사인 유사도(cosine similiarity)라고 하여 벡터 간 유사도를 표현할 때 많이 사용된다.
Query와 Key 가 완벽하게 일치하면 1을 반환할 것이고, 불일치한다면 0을 반환하기 때문에 Query-Key 라는 표현으로
Query-Key는 다른 레이어로 각각 학습되면서 서로에게 물어보는 것으로 보였다.
Value 레이어는 이를 좀 더 보완해주는 형태로 보였는데, 학습 과정 속에서 이런 설계를 만들었다는 게 인상깊었다.
개인적으로 트랜스포머를 읽으면서 코드를 짜보면 재밌을 것 같아서 한번 코드를 짜봐야겠다.